
Read insights, thought leadership, and platform updates.
No Blogs Match Your Results
Please try again or contact marketing@threatconnect.com for more information on our blogs.
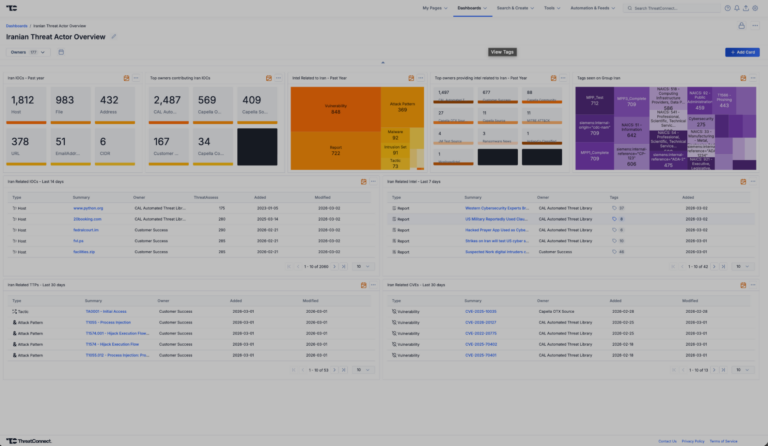
Iranian Conflict Intelligence Dashboard Immediately Available for ThreatConnect
The escalation of geopolitical tensions specifically focused on the Iranian Conflict over the last days of February 2026 has intensified the significant cyber and physical security risks to organizations globally. With threat activity emanating from advanced Iranian state-sponsored actors, aligned hacktivist collectives, and opportunistic criminal groups, security teams must remain agile, informed, and proactive. The […]

From Noise to Signal: Crafting TI-Informed Detections for Real Security Value
A Practical Guide for MSSPs to Turn Alert Noise into Defensible Security Outcomes Managed Security Service Providers (MSSPs) generate an enormous volume of alerts every day. Yet many MSSP customers still ask the same question: “What did this actually protect us from?” This gap between alert activity and perceived security value has become one of […]

Prioritizing Vulnerabilities That Actually Matter
Why Vulnerability Prioritization Breaks Down for MSSPs — and How the Best Are Fixing It When 95% of organizations are falling short of response time best practices, MSSPs who can consistently reduce mean time to respond (MTTR) don’t just improve security outcomes — they win and retain customers. But faster response doesn’t come from more […]
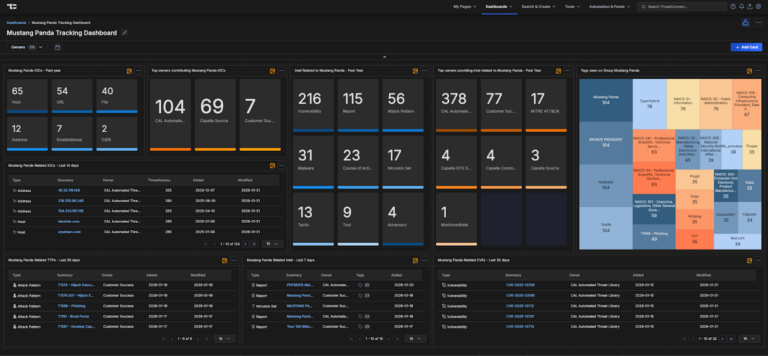
Mustang Panda Intelligence Dashboard Immediately Available for ThreatConnect
Mustang Panda—also known in industry and government reporting as BASIN, BRONZE PRESIDENT, CAMARO DRAGON, EARTH PRETA, FIREANT, G0129, HIVE015, HoneyMyte, LUMINOUS MOTH, Polaris, RedDelta, STATELY TAURUS, TA416, TANTALUM, TEMP.HEX, TWILL TYPHOON, or UNC6384—is a highly active, state-sponsored Chinese cyber-espionage group assessed to operate under the People’s Republic of China (PRC). Active for over a decade, […]

Why ThreatConnect’s VP of Product Marketing Spends His Off Hours Rescuing Wild Foxes
The Advanced Persistent Talent series profiles ThreatConnect employees and explores how their work impacts products and offerings, how they got here, and their views on the industry at large. Want to know more about a particular team? Let us know! As a seasoned marketer in the cybersecurity space, Dan Cole has heard all of the […]

ThreatConnect Customer Success Engineer Angel Salcedo Makes Success a Team Sport
The Advanced Persistent Talent series profiles ThreatConnect employees and explores how their work impacts products and offerings, how they got here, and their views on the industry at large. Want to know more about a particular team? Let us know! Angel Salcedo radiates energy even through a computer screen. The warmth in his smile and […]

How Threat-Informed Response Slashes MTTR and Boosts MSSP Margins
The hard reality for Managed Security Services Providers (MSSPs) is that customers today expect faster answers, higher visibility into threats, and total confidence that their provider can separate signal from noise. Meanwhile, alert volume continues to surge across SIEM, EDR, XDR, and cloud telemetry while SOC teams remain understaffed and overwhelmed. This perfect storm of […]

How ThreatConnect Senior Security Engineer Matt Brash Rescues SOC Teams from Burnout
The Advanced Persistent Talent series profiles ThreatConnect employees and explores how their work impacts products and offerings, how they got here, and their views on the industry at large. Want to know more about a particular team? Let us know! How does a biochemistry diplomate wind up working in cybersecurity? For ThreatConnect Senior Security Engineer […]

Empower Seamless Collaboration with Polarity’s RFI Integration
A smarter, faster way for security teams to share context, reduce friction, and accelerate action. Security teams are drowning in alerts, overwhelmed by disconnected tools, and constantly scrambling to get the right information to the right people. Incident response, threat intel, vulnerability management, procurement, and HR all work in different tools — often with zero […]

CAL, MITRE v18 & MITRE ATLAS: The Map I Wish I Had in the SOC
The map I wish I had in the SOC I remember a Thursday night at a previous SOC position in FinTech. The alert queue spiked during a credential stuffing incident, and our team had to scramble to keep up with the influx of alerts. We had a SIEM, a SOAR, and a handful of open-source […]
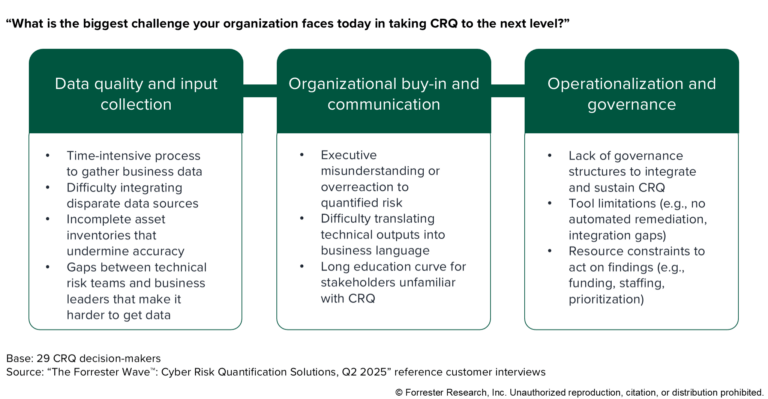
Part 2: Putting Cyber Risk Quantification Into Action: Moving Beyond Theory
This blog post is a continuation of our blog post Putting Cyber Risk Quantification Into Action: Moving Beyond Theory. In part one, we explored how Cyber Risk Quantification (CRQ) has evolved from theory to practice, focusing on the key choice between manual estimates and automated, data-driven approaches. We discussed how CRQ’s real value lies in […]
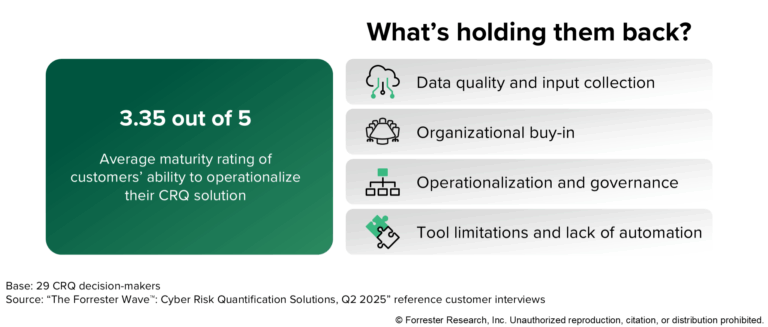
Putting Cyber Risk Quantification Into Action: Moving Beyond Theory
The cybersecurity industry has reached an inflection point. According to the Forrester Buyer’s Guide: Cyber Risk Quantification Solutions, 2025, organizations are moving beyond theoretical discussions about cyber risk quantification (CRQ) and focusing on operationalization. But what does it really mean to put CRQ into action, and why are so many companies wishing they’d started sooner? […]