Posted
This is Part 2 of the Best Practices for Writing Playbooks in ThreatConnect blog post series. This time, I wanted to get into the weeds on some best practices for development and testing. If you haven’t already read it, I highly recommend taking a minute and reading Part 1, here.
To Playbook or not to Playbook, that is the question
To effectively leverage Playbooks, it first helps to understand what Playbooks are really meant to do. ThreatConnect’s Playbooks capability was designed to help analysts orchestrate and automate repetitive workflow-based tasks that would otherwise take up time spent performing analysis. Sometimes we see Playbooks looked to as a catch-all solution for any sort of data processing, and this can definitely lead to a lot of misconceptions and potential performance issues.
Below are a few tasks that Playbooks are NOT the ideal solution to handle:
- Handling mass quantities of big data
- Acting as as a message bus
- Performing in-depth automated malware sandboxing (basic triage is totally on the table, see below)
To contrast, here are a few things that Playbooks are a GREAT solution for:
- Phishing email parsing and analysis
- IOC enrichment
- Customized incident ticketing and alerting
- Basic malware triage (pulling strings, metadata, zipping up and sending to an AMA, etc.)
Pump up the volume…carefully
“I’ve seen things you people wouldn’t believe. Phishing Email Triage Playbooks with 57 apps off the coast of Microsoft Outlook. I watched a hundred thousand REST API calls glitter in the dark near the VirusTotal AV pool. All those Playbook executions will be lost in the queue. Like tears in the rain. Time to reboot.”
-Roy Batty (during his SOC Analyst days)
Playbooks can be a very powerful force multiplier, but with that power comes the potential for very high resource utilization if not employed properly. Playbooks that have a highly complex design path, get thrown an overabundance of data to work through, or get executed too many times have the potential to bring even the beefiest of systems to a crawl. Or worse, crash the ThreatConnect instance entirely (been there, done that, got yelled at by DevOps).
One of the most common Playbooks use cases out there is IOC enrichment, which on the surface sounds pretty cut and dry, right? I mean, who wouldn’t want more enrichment and context for their IOCs?! The issue is that a lot of times, I see analysts writing Playbooks that trigger whenever a particular type of IOC is created in their instance. This can cause issues if you’re triggering on IOC creation in a data source that you don’t really have control over. OSINT feeds, for example, can quite often produce thousands of new IOCs per day. I’ve also seen some premium intelligence vendor feeds produce tens of thousands of new IOCs per day! This means that if you’ve designed your Playbook to trigger on each new IOC being created, you’re easily gonna queue up a few thousand Playbook executions and not even realize it.
Instead, think about ways you can pare down the execution count. Are the new IOCs being created as part of an associated Group such as a new Report, Campaign, or Incident? If so, you should explore triggering off of said Group creation, then taking the associated set of IOCs and enriching those all at the same time. Doing that, you’re talking one Playbook execution handling multiple IOCs instead of a single execution per IOC.
Additionally, think about triggering on conditions such as IOCs or Groups being tagged with a particular keyword. This is a great method because you’re taking data that already has a good chance of being relevant to you, and enriching it even further
I can promise you that if you just throw 200k executions of a particular Playbook at ThreatConnect and expect them to be completed immediately, you’re setting yourself up for disappointment!
A Variable Has No Name
Variable naming matters. You should be documenting what the variables that you’re creating are, but ideally a user should be able to have a reasonably good understanding of what it is just by the variable name. Keeping a consistent variable naming scheme is highly recommended. Not only does this make for a cleaner Playbook, but also it’s super helpful when you have to debug failed Playbook executions. Below are a few examples of times where good variable naming should come into play:
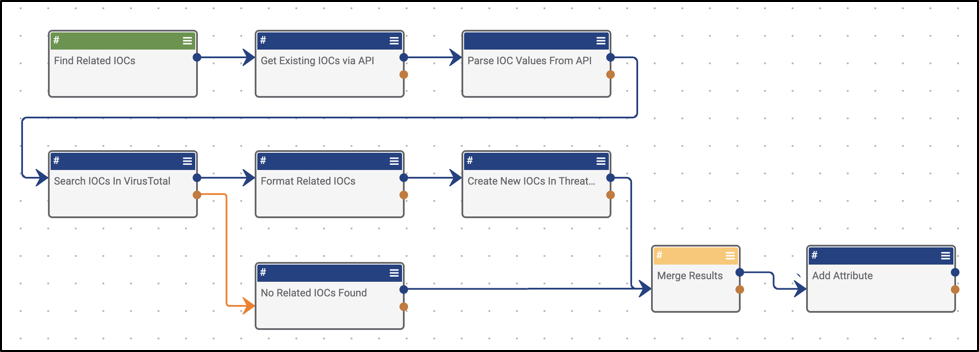
- Using the Merge operator to merge two variables from upstream apps, it’s best practice to prepend the new variable with the letter “m” or “merged” (Figure 1).
- Example: Merging the two potential outcomes of an API call. In a success scenario, you will get a response, and then likely do some sort of parsing out of a value. There is the potential that the API call will fail, in which case you may want to use something like a Set Variable app to denote said failure.
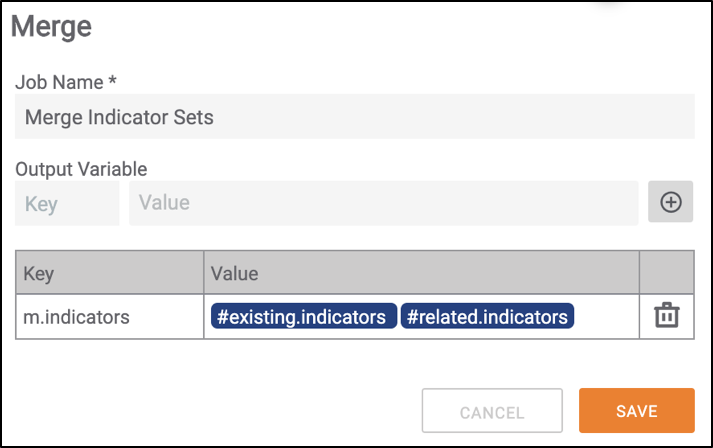
Figure 1
- When using the Split String app, it’s a good idea to prepend the newly created variable with something like “s” or “split” (e.g. splitting the String variable “#url.values” would return a StringArray named “#s.url.values” or “#split.url.values”). Same goes for Join Array using “j” or “join”.
Keep Calm And Handle Your Errors
Apps fail, it happens. Don’t take it personally. I’m sure you’re a very nice person.
It’s really easy as Playbook developers to fall into the bad habit of “developing for success”. We will just keep building until you get that sweet sweet green dot indicating that your Playbook works and then call it a day. As weird as this sounds, this is actually a really bad habit! Obviously, developing with the goal of having a Resource that runs successfully is great, but the trap lies in the act of stopping development when you have a successful running Playbook. You’re only halfway done. You should be writing your Playbook to handle the eventuality that things are NOT always going to go according to plan.
Keep your blue dots close, but your orange dots closer
Every app has two possible exit conditions denoted by dots on the right side of the app icon itself (blue for success and orange for failure). The orange dot is there for a reason, so don’t be afraid to use it.
Sometimes you may expect an app to fail, in which case there’s more than likely separate logic you’ll want to run. Just don’t forget to merge the two potential paths. One great example of this is merging the two potential outcomes of an API call. In a success scenario, you will get a response, and then likely do some sort of parsing out of a value. There is the potential that the API call will return no results, in which case you may want to use something like a Set Variable app to denote said failure with a “No API Results Found” (Figure 2).
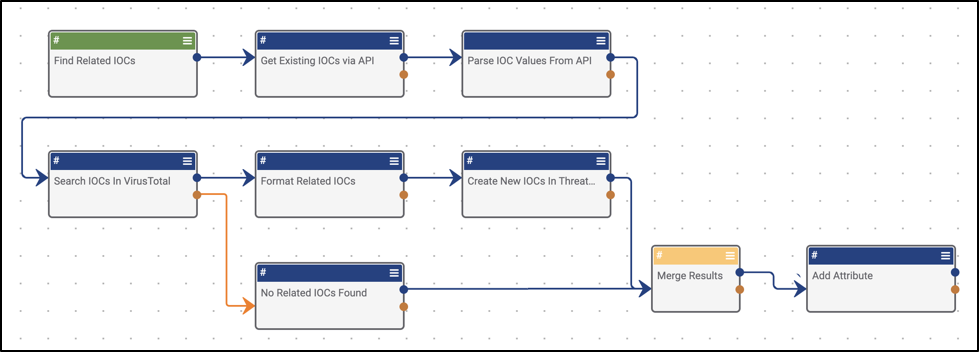
Figure 2
“You know how you get to Carnegie Hall, don’tcha? Practice.”
I hope everyone is testing their Playbooks thoroughly before turning them on! If not…well, that’s a bold strategy, Cotton. Let’s see if it pays off. Testing should occur not only during development process, but especially during QA and UAT. If you remember from Part One of this blog series, Playbooks should be treated like production level automations. The number one rule of delivering quality products is to perform adequate quality control and testing.
For those of you that ARE doing testing, kudos! That being said, let’s go through some tips and tricks to make sure you’re getting the most out of your testing.
“Use the Logs, Luke.”
ThreatConnect has a VERY robust logging mechanism that’s absolutely crucial for proper development and testing. By default, the logging verbosity is minimal for performance reasons (especially when executing hundreds or thousands of Playbooks each with 5+ apps), but the logging level can be raised to DEBUG or TRACE to see everything that’s happening.
!!!WARNING!!!
Please, for the love of all that is holy, DO NOT leave your Playbook on TRACE logging after your testing is done. Depending on the complexity of the Playbook and amount of executions, you can quite easily produce gigabytes of logs and fill up a hard disk. This kills the ThreatConnect. Ask me how I know.
!!!WARNING!!!
One of the best logging features ThreatConnect offers, in my opinion, is the ability to watch the actual values being passed between Playbook apps. This is extremely useful because you may find yourself in a situation where a certain app is failing and you have no idea why. Then, using the variable value inspection feature you can see what’s actually being sent. You can view both the input values of a given App or Component as well as the output values (Figures 3 and 4):
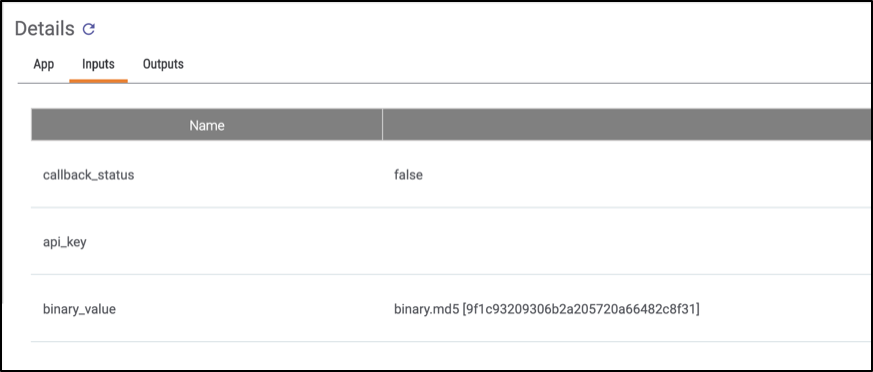
Figure 3
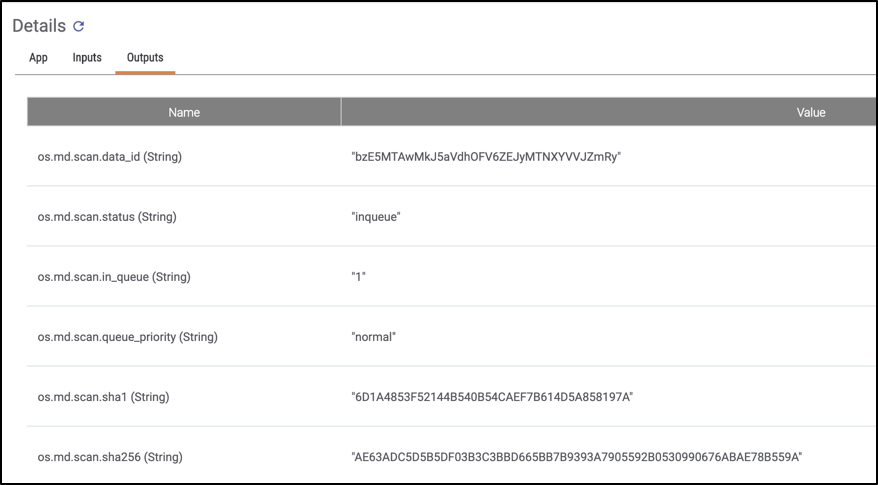
Figure 4
To give you a real world example; I have personally found numerous mistakes in regular expressions that I’ve written because what was actually being parsed out was different than what I (and other downstream apps) was expecting.
- Verifying that you’re not passing in NULL data into a “Create X” app is an integral part of development and testing.
“Efficiency is intelligent laziness.”
As technology practitioners, we should always strive to be as efficient as possible. This need is especially prevalent when dealing with any sort of automation at scale because you can quite easily be dealing with hundreds, thousands, or even tens of thousands of Playbook executions. Any efficiency you can squeeze out of your Playbook is going to immediately pay dividends in the form of better execution throughput.
There’s no magic bullet for making the most efficient Playbooks. Learning how to be efficient with Playbooks comes with time and practice. That being said, below are a few tips that can help get you started:
- Duplication of effort: Find yourself redoing the same steps over and over again? Try building those steps into a Component for easy reuse! Don’t know what a Component is? Check this video out: https://www.youtube.com/watch?v=6axA-farO1I
- Excessive branching: Pay attention to how much you branch in a single Playbook. There are limits in ThreatConnect that regulate the amount of concurrent branches can be executed at any one time. Any branches over that limit are going to be queued up and won’t execute simultaneously, therefore slowing the overall execution of the Playbook down. Sometimes branching more than 4 times is unavoidable, but just keep in mind that if possible consolidate branches where you can.
- Set Operations vs Iterators: Whenever possible use Set based operations instead of Iterators. When dealing with large amounts of data you pay a performance penalty when using Iterators.
- e.g. Using the Create ThreatConnect Tag app and sending a StringArray of 100 indicators is going to MUCH more efficient than using the Iterator to loop through each element of the StringArray and adding the tag one at a time.
- Resource Monitoring: Be mindful of system resource utilization with intensive Playbooks. Resource usage can be monitored via the Activity page (Figure 5). Definitely keep an eye on this when doing your testing.
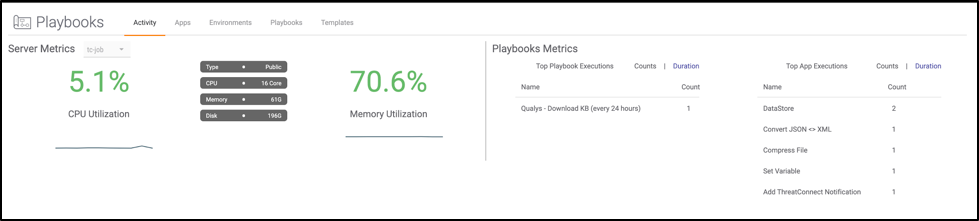
Figure 5
And with that, we come to the end of this blog series. You should now be able to design, create, name, and test high quality Playbooks right?
Good.
Now, get off my lawn!